Abstract
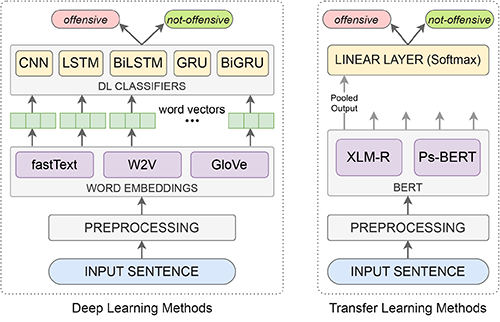
Social media platforms have become inundated with offensive language. This issue must be addressed for the growth of online social networks (OSNs) and a healthy online environment. While significant research has been devoted to identifying toxic content in major languages like English, this remains an open area of research in the low-resource Pashto language. This study aims to develop an AI model for the automatic detection of offensive textual content in Pashto. To achieve this goal, we have developed a benchmark dataset called the Pashto Offensive Language Dataset (POLD), which comprises tweets collected from Twitter and manually classified into two categories: “offensive” and “not offensive”. To discriminate these two categories, we investigated the classic deep learning classifiers based on neural networks, including CNNs and RNNs, using static word embeddings: Word2Vec, fastText, and GloVe as features. Furthermore, we examined two transfer learning approaches. In the first approach, we fine-tuned the pre-trained multilingual language model, XLM-R, using the POLD dataset, whereas, in the second approach, we trained a monolingual BERT model for Pashto from scratch using a custom-developed text corpus. Pashto BERT was then fine-tuned similarly to XLM-R. The performance of all the deep learning and transformer learning models was evaluated using the POLD dataset. The experimental results demonstrate that our pre-trained Pashto BERT model outperforms the other models, achieving an F1-score of 94.34% and an accuracy of 94.77%.
Full Paper: https://doi.org/10.7717/peerj-cs.1617