Abstract
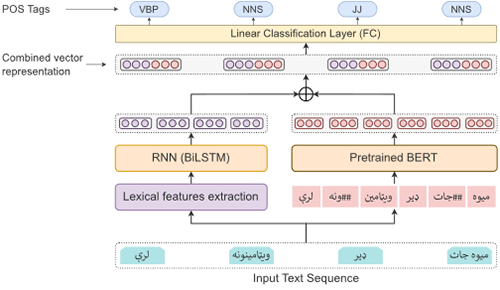
In this study we developed a corpus of the low-resource language – Pashto. The corpus consists of 5 million words, labeled for explicit word-boundaries. And at the time of writing this paper, around 2 million of the words are tagged for Part-of-speech (POS) information. Pashto has no explicit word-delimiter like whitespace in English. The word-boundary markers added to the corpus are not only useful in this study for splitting the text into words, but can also be used in the development of a specialized word segmenter for Pashto. The process of POS tagging was carried out in several rounds where each Round has two sub phases, the automatic POS assignment and manual correction. A specialized web application is developed for manual correction and quality control. The tagset used for tagging is very concise and pragmatic that is developed on the guidelines compatible with the previous standard corpora. In the first Round, the baseline Lexicon-based approach was used for tagging a chunk of 230K word and then manually corrected. Using these tagged words as training data, a Machine Learning (ML) model was trained for tagging the remaining corpus. The purpose of incorporating ML was to improve the accuracy of automatic POS assignment, thus to speed-up the tagging process and reduce the manual effort. Tagging results of the final ML-based model are very satisfactory, which yields an accuracy of 99% and F1-score of 98%. Besides building an automatic POS tagger, the proposed corpus is aimed to be used in countless open research areas in Pashto NLP such as homographs disambiguation, NER, word segmentation, text proofing, constituency and dependency parsing and language modeling etc.
Full Paper: https://doi.org/10.21203/rs.3.rs-2712906/v1