Abstract
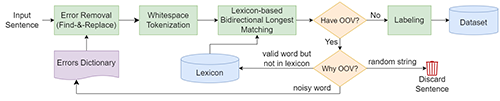
Word segmentation is the process of splitting up the text into words. In English and most European languages, word boundaries are identified by whitespace, while in Pashto, there is no explicit word delimiter. Pashto uses whitespace for word separation but not consistently, and it cannot be considered a reliable word-boundary identifier. This inconsistency makes the Pashto word segmentation unique and challenging. Moreover, Pashto is a low-resource, non-standardized language with no established rules for the correct usage of whitespace that leads to two typical spelling errors, space-omission, and space-insertion. These errors significantly affect the performance of the word segmenter This study aims to develop a state-of-the-art word segmenter for Pashto, with a proofing tool to identify and correct the position of space in a noisy text. The CRF algorithm is incorporated to train two machine learning models for these tasks. For models’ training, we have developed a text corpus of nearly 3.5 million words, annotated for the correct positions of spaces and explicit word boundary information using a lexicon-based technique, and then manually checked for errors. The experimental results of the model are very satisfactory, where the F1-scores are 99.2% and 96.7% for the proofing model and word segmenter, respectively.
Full Paper: https://doi.org/10.1016/j.specom.2023.102970